Architecture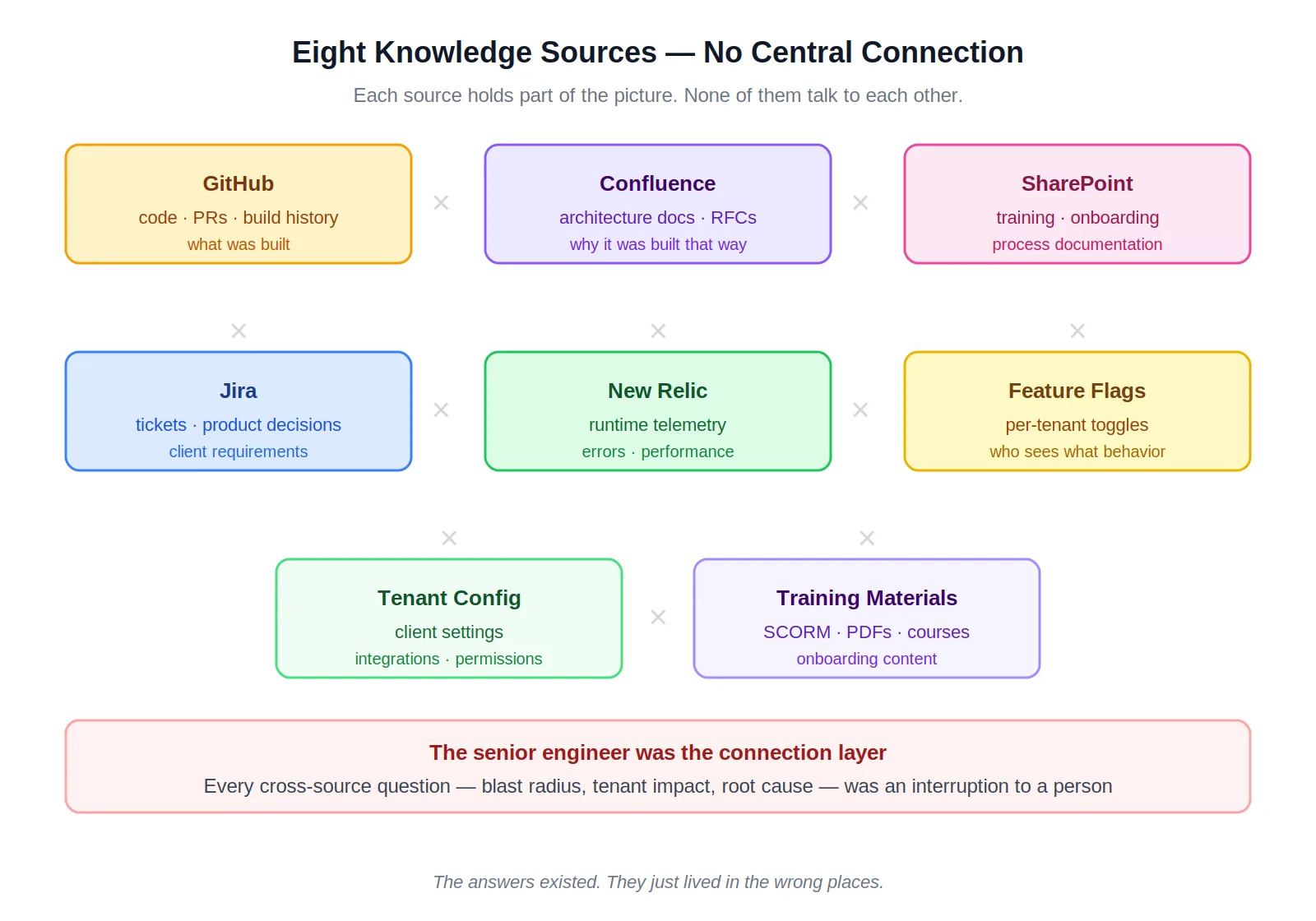
Architecture
When Your Codebase Becomes a Knowledge Problem
A large-scale .NET platform with eight enterprise knowledge sources — code, documentation, pull requests, database schemas, telemetry, feature flags, tenant configuration, training materials — and no central way for engineers to understand how any of it connected. AI tools could parse the code. What they couldn't tell you was why a feature existed, which tenants it affected, how feature flags altered behavior per client, or what the blast radius of a given change would be. Senior engineers filled that gap. This system replaced them as the answer layer — and compliance requirements shaped the hardest decision in building it.
3–5 min read
Key Tradeoffs
- Code alone answers what exists. You need product decisions, client configurations, and operational context to answer why—and those live scattered across systems AI tools can't correlate.
- Compliance requirements forced local embeddings over hosted APIs. Rather than accepting single-vendor lock-in, abstract the embedding layer so you can swap implementations without rewriting the system.
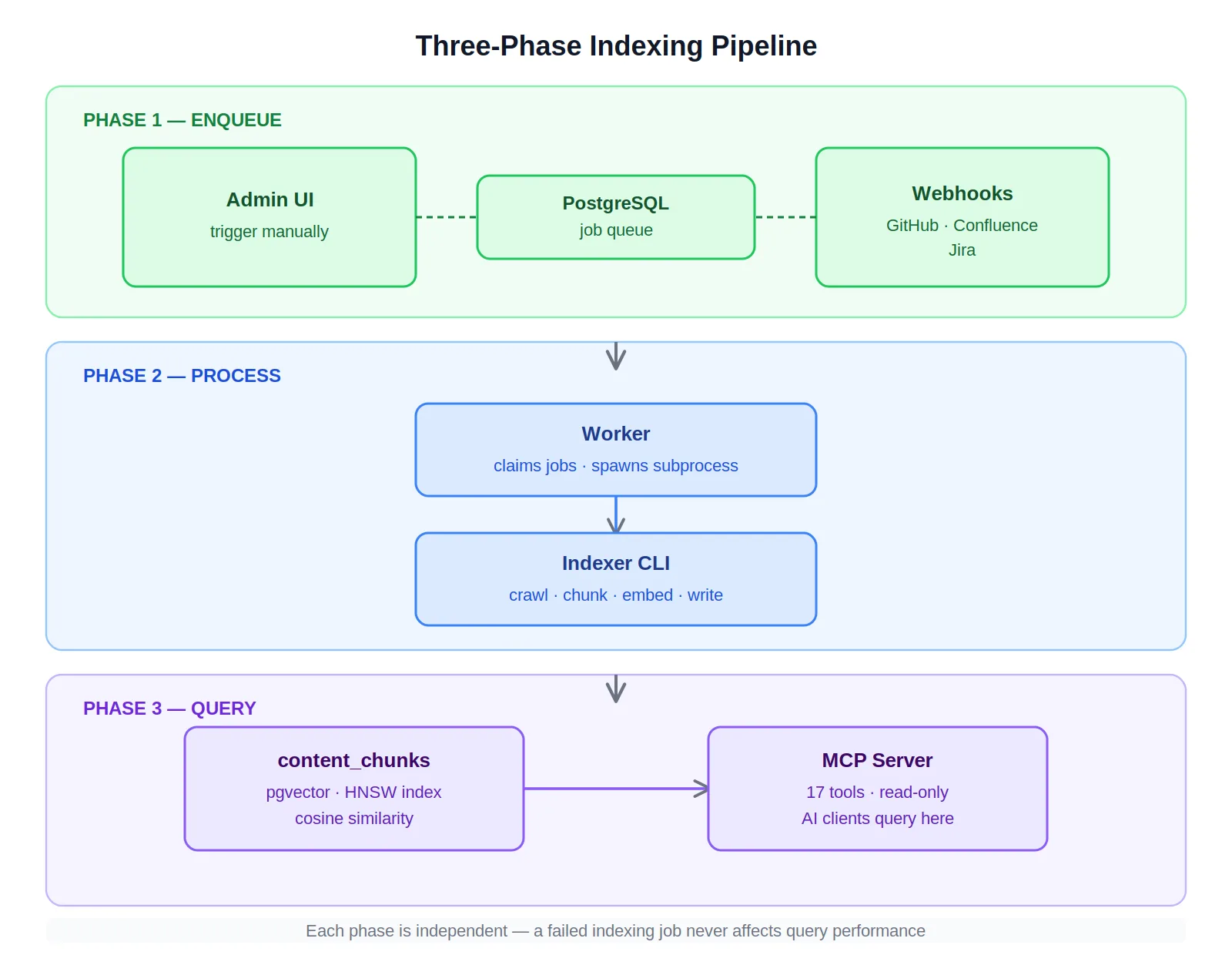
- Separate enqueueing, processing, and querying into independent phases sharing only a database. One bad data source crashes a subprocess, not the pipeline. A slow query doesn't degrade indexing.
- Plugin architecture wins when sources multiply. Define a clear interface (IIndexerPlugin), discover at runtime, add sources without touching Core or Worker—your capacity to grow lives at the boundary.
- Incremental indexing by content hash means webhooks trigger only what changed. Full rebuilds waste compute and embeddings. Target re-indexing keeps your index current without paying the cost on every commit.
What Happened
The knowledge problem on a mature platform isn't usually that documentation doesn't exist. It's that it lives in six places, none of them cross-referenced, and the relationship between them only exists in the heads of the people who built it.
Confluence held the architecture decisions. GitHub held the implementation history. SharePoint held training materials. Jira held the product reasoning and client-specific decisions. New Relic held the runtime behavior. Feature flag definitions and tenant configuration were scattered across systems that only senior engineers fully understood.
The result was a specific and recurring failure mode. When a production bug surfaced, tracing which recent PRs, merges, or GitHub Actions builds might have caused it required manually correlating across four tools. When a new feature was being scoped, understanding which tenants would be affected — and how their configurations would interact with the change — required asking someone who'd been there long enough to know. AI tools hit the same ceiling. They could reason about the implementation. They couldn't reason about the product decisions, client configurations, and operational context that explained why the implementation looked the way it did. Code alone is half the picture.
How It Was Addressed
The goal was a RAG system that indexed every knowledge source and exposed the full corpus to AI clients through a standard interface — so that questions like "what recent changes could have caused this production issue" or "which tenants does this change affect" returned answers drawing from code, PRs, Jira history, and tenant configuration simultaneously.
I built this as a solo project across five .NET components: a shared Core library, a CLI Indexer, a background Worker, an Admin web UI, and an MCP Server exposing 17 tools to AI clients.
The hardest decision was local embeddings over OpenAI's hosted API. The compliance requirements were unambiguous: confidential information and PII could not leave the network. OpenAI's embedding API was off the table. Rather than accepting lock-in to a single local provider, I built an abstraction layer — OllamaEmbeddingService and OpenAiEmbeddingService sitting behind the same interface, swappable via config. The system runs fully on-premises, fully on Azure OpenAI, or split across both. Compliance requirements drove the decision. The abstraction made it livable. The tradeoffs of running local embeddings in production are real and worth understanding before committing to the approach.