The Abstraction Layer as the Answer
Rather than accepting lock-in to either option, I built an abstraction layer that made the embedding provider a configuration decision rather than an architectural one.
The pipeline routes through TrackingEmbeddingService — which wraps usage metrics around any provider — and optionally through RoundRobinEmbeddingService for multi-endpoint load balancing. The concrete implementations, OllamaEmbeddingService and OpenAiEmbeddingService, sit behind the same interface. Swapping providers doesn't touch the indexing pipeline, the query path, or the storage layer. It changes a config value.
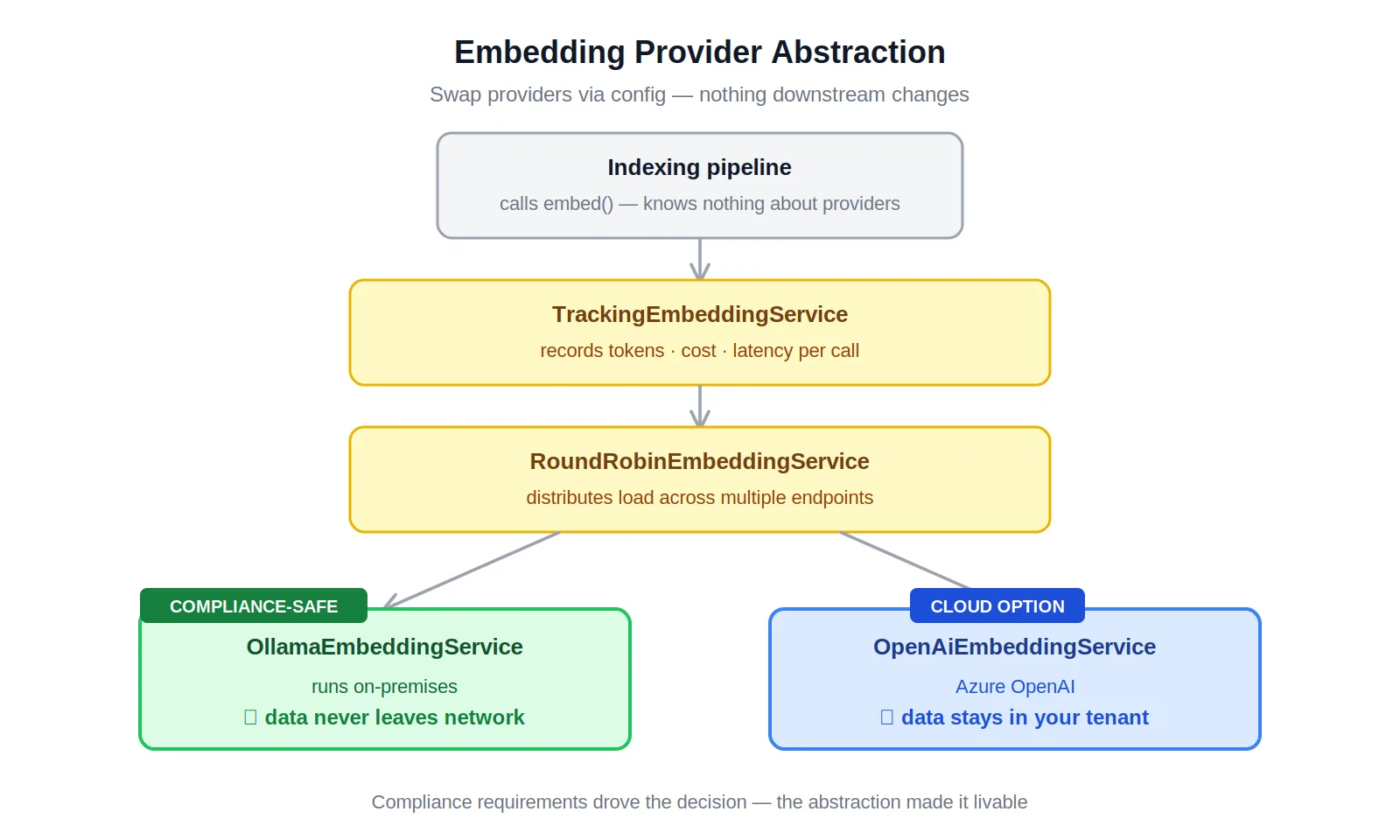
The result is a system that can run fully on-premises with Ollama, fully on Azure OpenAI, or split across both — with different providers for different workloads if the compliance posture or performance requirements call for it. As models improve, as compliance guidance evolves, as Azure OpenAI achieves certification for additional regulatory frameworks, the system adapts without an architectural change.
Compliance drove the requirement. The abstraction made it livable — and made the system more adaptable than it would have been if the decision had been made under no pressure at all.